As you have probably already gathered I’m a big fan of Analytics and Visualisations so when my colleague Manuel Altermatt told me he was doing some work on CRM and Data Mining and wanted to do a guest post I jumped at the chance! You can contact manuel on analyticalcrm@outlook.com.
Whilst Dynamics CRM is widely recognized for its strong operational capabilities, the outstanding analytical capabilities which arise in conjunction with SQL Server are sometimes overlooked. We can think about business intelligence in two categories:
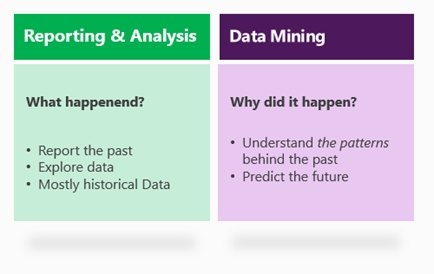
Reporting and analytics, which are methodologies and tools that focus on “what happened”, thus working on data exploration, historical information, reports, dashboards, KPI’s, etc.
Data Mining, which are methodologies and tools that focus on “why did it happen”, thus working on data understanding, patterns, correlation, past and future data, and data prediction.
This blog post shows how Dynamics CRM can be combined with SQL Server to create some remarkable scenarios around data mining and data prediction.
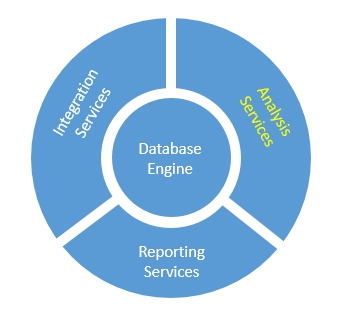
SQL Server Analysis Services (SSAS) is part of SQL’s fundamental framework and offers a wide set of tools and methodologies for data analysis. In particular, SSAS contains various capabilities around SQL data mining, including 9 advanced algorithms for data analysis. The discussion of each algorithm goes well beyond the scope of this post (and my limited understanding of statistics), but we will tackle a few algorithms for the example below.
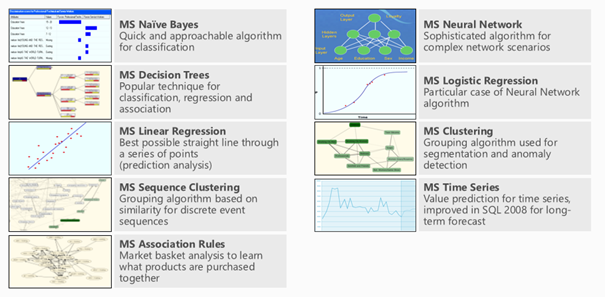
Before we get started, let’s quickly review a general and common approach to data mining. We will follow these steps in the example below.
- Understand your data. A data source – in this example. Dynamics CRM – holds transactional information generated by daily business. This is the data that we want to analyze. For example, we could be looking at customers of a supermarket or teleco provider.
- Extract your data. Since we may need to combine the transactional data with some additional data, plus also data analysis can have a large performance impact on your CRM system, the data is usually extracted and put in a Data Mart or Data Warehouse. This is where the data mining will happen. Notice that Dynamics CRM offers numerous ways for data extraction, such as file export, access to the SQL tables, API’s, etc.
- Enrich your data. The data is quite often enriched with additional data, which can either be owned and generated by the company, or also imported from third party sources such as the Internet, Azure Marketplace, etc. Read here for some great examples on how easy it is to integrate different sources of data thanks to PowerPivot. For example, you may want to enrich your customer data with some demographic information related to the area where they life.
- Analyse your data. This is the critical step, and it’s actually a lot of magic simplified for the sake of this post. Basically the SQL algroithms allow you to:
- a. Define a model by selecting both an algorithm as well as the relevant pieces of information for your model.
- b. Train the model based on some historical data, thus fine-tuning the inner parameters of the model based on your data.
- Predict your data. Use the model to predict the outcome of new data. For example, you may predict possible upsale opportunities (aka leads), or customers who are at risk of canceling your contract.
- Import your data. The new generated information (eg. leads or risk flags) are then imported back into the CRM for operational action.
let’s look at a real-life example. Imagine the scenario of a retail bank that wants to get a better understanding of their AAA customer (“how can we know a AAA customer when we see one?”) as well as generate some possible leads for upsell opportunities. We will follow the suggested approach above.
Let’s talk about infrastructure first: For the CRM part, I built this example based on Dynamics CRM Online. For simplicity, I used the one-click CRM Demobuilder with the basic demo and some slight customizations (see data below). Since CRM Online does not offer direct access to the underlying SQL Database and its SSAS component, we need a separate instance of SQL Server for our data warehouse. Again, using the cloud: I used Azure and created a virtual machine with Windows Server 2008 and SQL 2008. Pick the one from the VM cataloge and you will be up and running in less than 5min. Last but not least, although the Data Mining algorithms can be access directly from within SSAS, I’m actually more of an Excel guy. I installed the Excel Data Mining Add-On on my Excel 2013 so I could surface the SQL algorithms from within Excel. You still need the power of SQL in the back, but you can access the algorithms comfortably from your Excel environment.
1. Understand your data
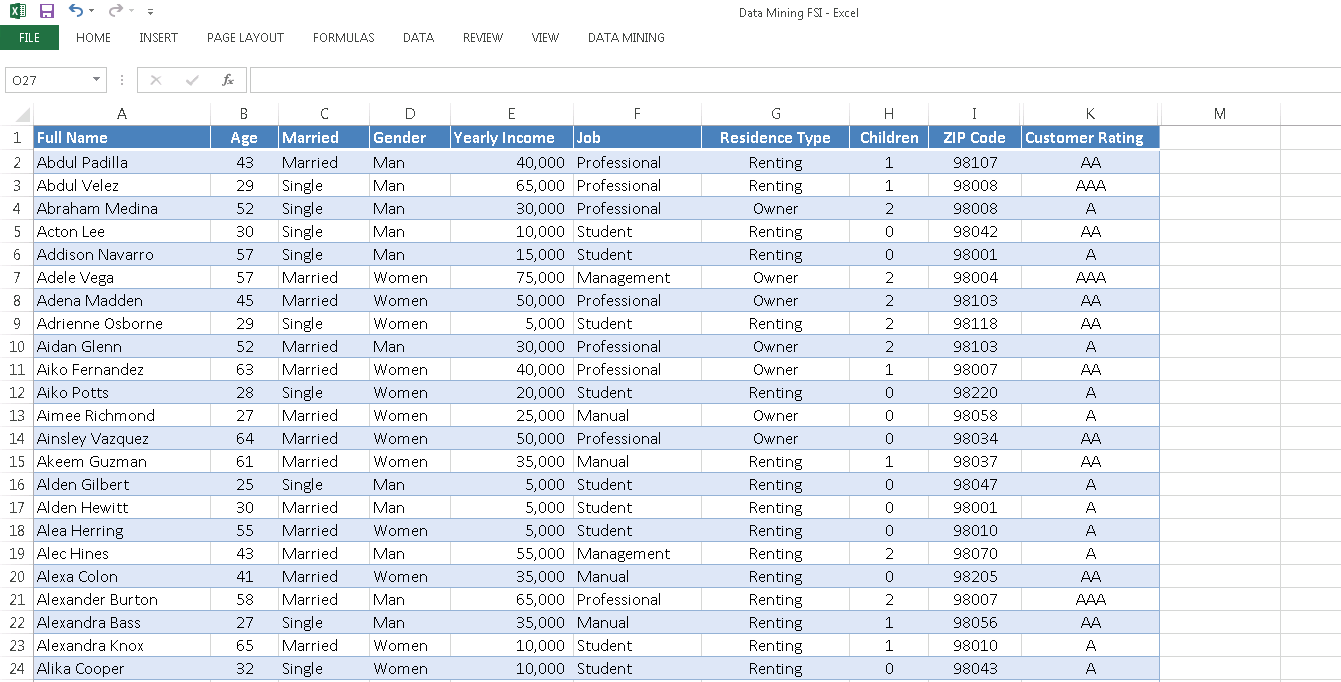
Here is a look at the CRM data. Notice that we have a number of important data fields for our analysis: Gender, Age, Yearly Income, Marital Status, Job, Residence Type, Number of Children, Address (ZIP Code) and Customer Rating (A, AA, AAA). We will try to uncover the hidden correlations between these fields to get a good predictor of the customer rating. Notice that we also have a linked table with the customer’s financial accounts.
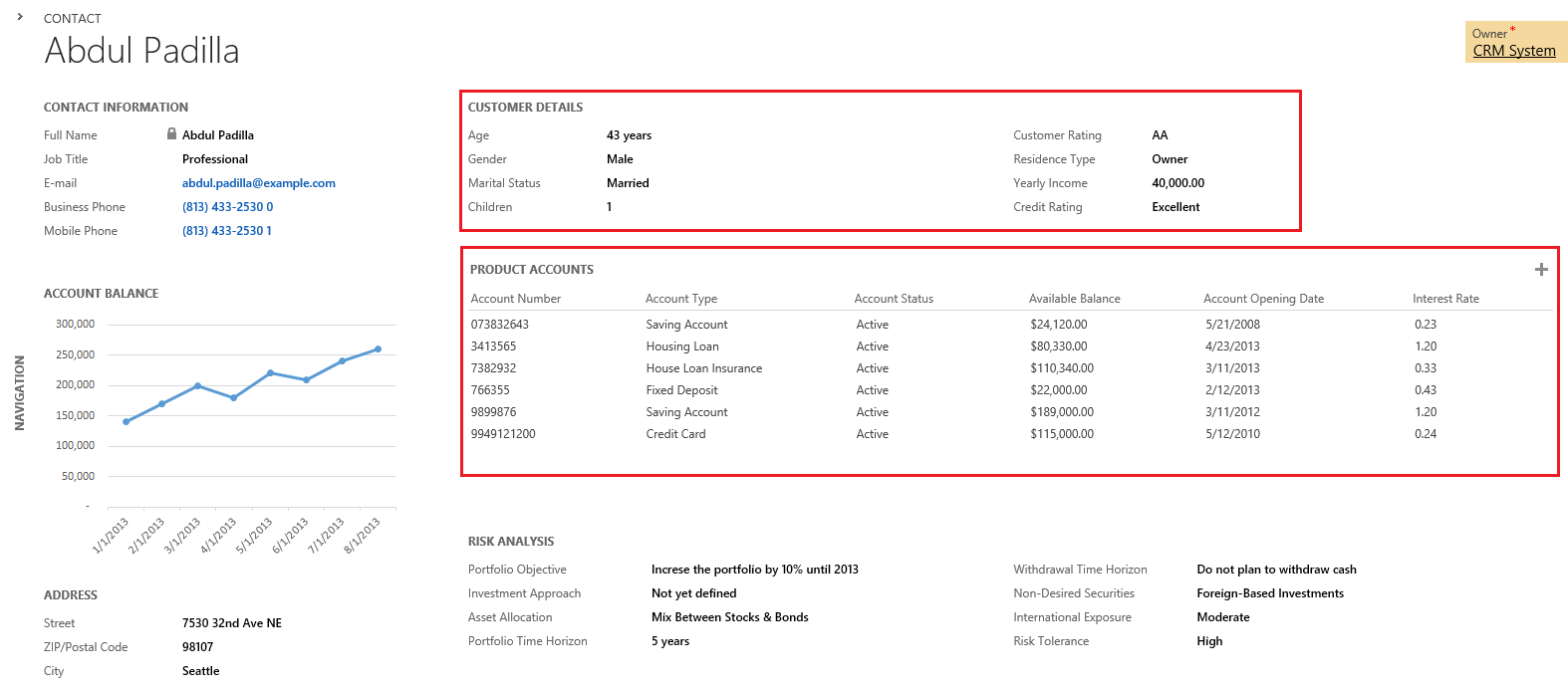
2. Extract your data
Data extraction and replication to the DWH can happen in many ways, including automated batch processes, API’s, etc. To keep this example simple, I’ve decided to do a simple file export/import. The contact entity is my main starting point. I will also need the associated financial accounts (custom entity), so I’ve exportet that too. Here is a look at our Excel export. Notice that we included all of the mentioned fields above.
 3. Enrich your data
3. Enrich your data
Insights come not only by considering the information that is already known, but by combining this with some new, external data. There are many ways to combine our data with external data – including good old VLOOKUP – but thankfully PowerPivot allows me to include external data sources directly into my data model.
Could the neighborhood of our customers hold some insight into their categorization and value for our bank? Maybe. So I’ve connected my data model with an Azure database that is free, publicly available and holds key demographic information for all US neighborhoods by ZIP Code. Here are some step-by-step instructions on how to include external demographic data into our table.
We’ve now enriched our customer table a new column: Average home value of houses in the corresponding neighbood (ZIP code).
 4. Analyse your data
4. Analyse your data
Once we’ve connect Excel to our SQL Database in the Azure Virtual Machine, we get access to the SQL Data Mining Algorithms right from the Excel Ribbon.


Using the first algorithm – Detect Categories – Excel can help us understand the high level segments of our customer base. In this case, we select the columns Age, Married, Gender, Income, Job, etc. We unselect the column “Full Name”, assuming that the categories do not correlate with customer names. Also we leave “Customer Rating” out of the picture for a moment as we want to understand our customer base unbiased from our own categories and ratings.
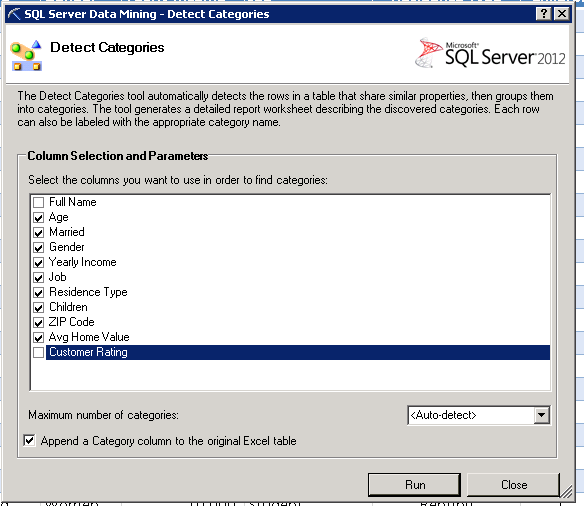
The analysis takes a few moments, but the results are worth the wait. Excel segments our customer base into 4 categories, providing us with the key factors to help us decide in which category a customer belongs. Notice the bars in column D? This is statistics, so everything is always weighted with some probability or importance.
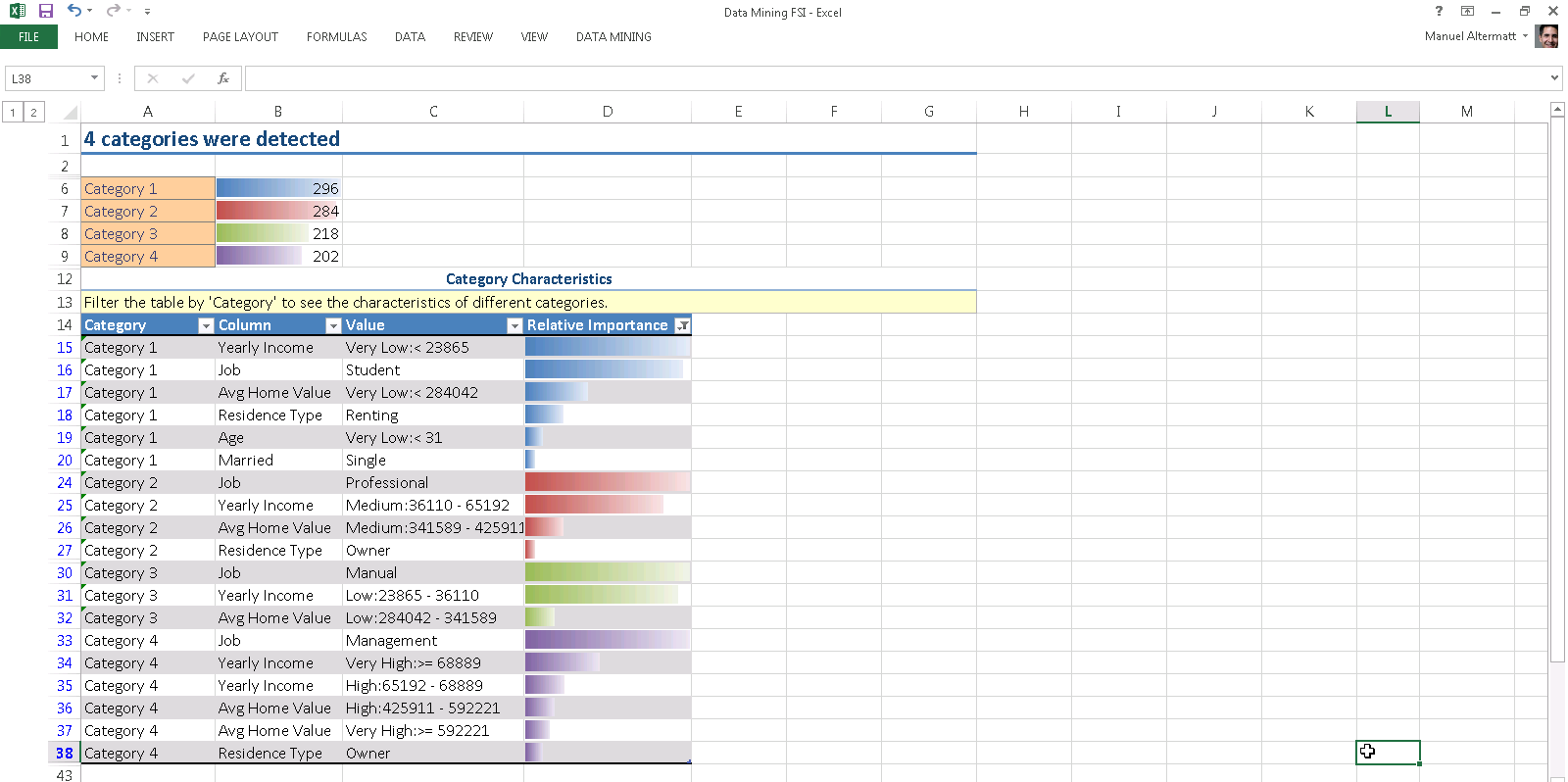 Here are the four categories in plain English.
Here are the four categories in plain English.
1. Category 1, aka “the Students”, consisting mostly of customers with very low income, student profession, young age, and renting residency.
2. Category 2, aka “the Professionals”, consisting mostly of customers with medium income, living in an neighborhood of medium home value and slightly biased to home owners.
3. Category 3, aka “the Middle Class”, consisting mostly of customers with manual labour low income, and living in neighborhoods of low home value.
4. Category 4, aka “the Upper Class”, consisting mostly of customers with very high income, management profession, house ownership and living in expensive neighborhoods.
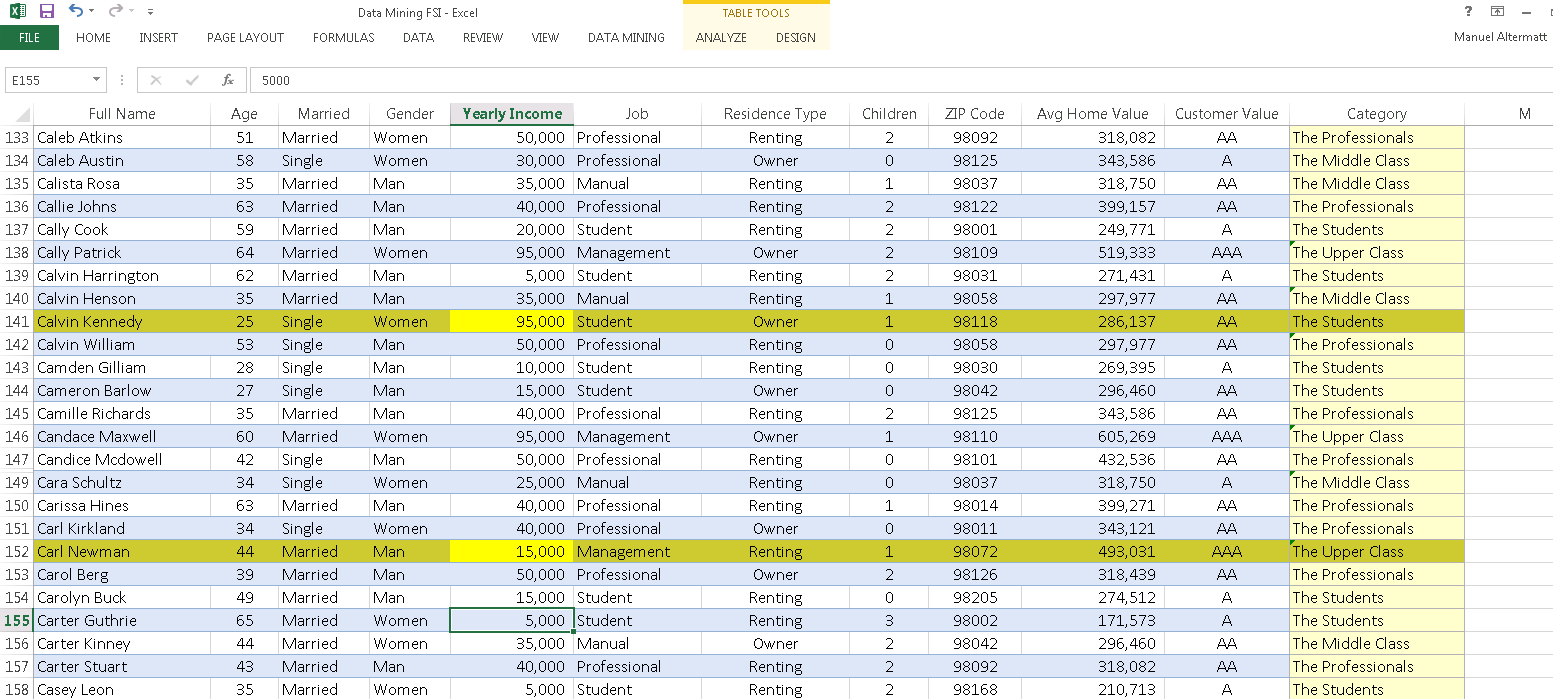
If you want, the algorithm can automatically detect and highlights exceptions. Notice the wealthy student and the low income CEO.
Our next algorithm – Analyze Key Influencers – should help us get a better understanding of our own internal ratings for our customers. The algorithm allows you to pick any column (“Customer Rating” for this example) and uncover the hidden correlations between the other columns and your column of choice. Let’s ee what are the key influencers for a A, double-A, or triple-A customer rating. Here is the result of the analysis:

The column “Favors” shows you the customer category. The column “Relative Impact” is again the statistical importance for every key indicator. As you can see, low yearly income as well young age and student profession favors a simple-A customer rating. On the other hand, income above 86k, management profession, ownership of a residence and a high value neighborhood favors a triple-A customer rating.
The analysis can be taken to the next level by analzying the decision tree and decision networks. This is priceless information for your next dynamic marketing list and marketing campaign.
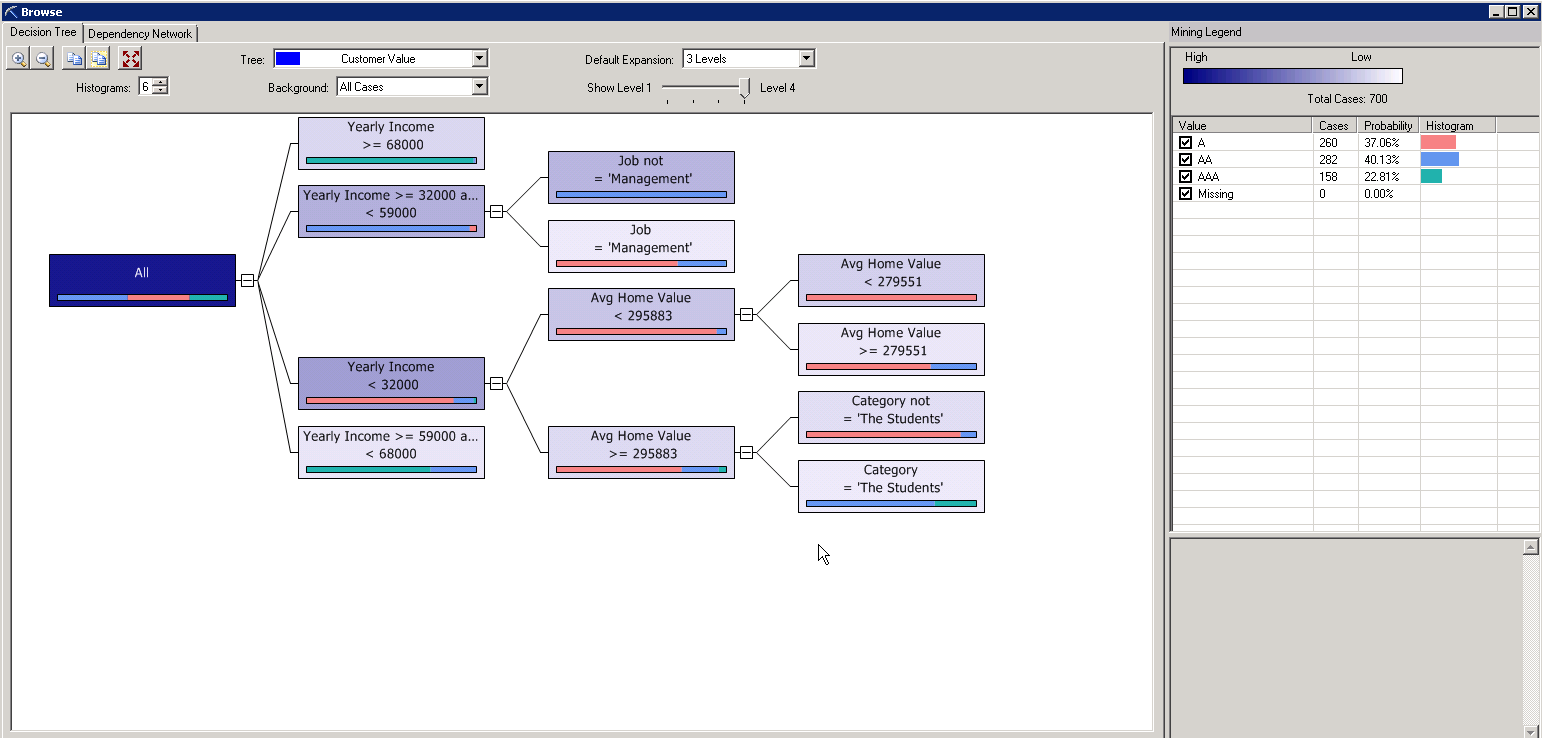
5. Predict your data
Any insight is typically useless if you cannot take action on it. So let’s go ahead and see if we can generate some upsell opportunities. For this example I’m using an export of the financial accounts of all customers. Column A holds the customer’s number. Column B is the account type. Column C is the yearly profit of the respective account.
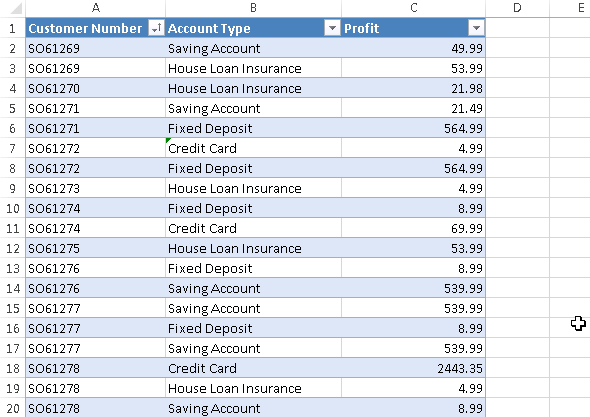
The basket analysis algorithm has its name from the retail industry and it will tell you which transactions are usually bundled together. Common belief is that you will find a pack of diapers and a pack of beer in the same shopping basket of a young father. Let’s use this algorithm on our data.

 Here is how you read the results (row 5): Housing Loans seem to be often in the same “basket” than House Loan Insurances. As a matter of fact, there are 3’249 Housing Loan Accounts. Out of these, 1’626 (or 50.05%) are attached to a House Loan Insurance Account. So there is some serious upsell potential of the remaining 1’623 House Loan Accounts which do not have an attached House Loan Insurance Account. Similar observations can be made for Saving Accounts and Credit Cards.
Here is how you read the results (row 5): Housing Loans seem to be often in the same “basket” than House Loan Insurances. As a matter of fact, there are 3’249 Housing Loan Accounts. Out of these, 1’626 (or 50.05%) are attached to a House Loan Insurance Account. So there is some serious upsell potential of the remaining 1’623 House Loan Accounts which do not have an attached House Loan Insurance Account. Similar observations can be made for Saving Accounts and Credit Cards.
This translates into well qualified opportunities.
6. Import your data
Now that we’ve gained a better understanding of who our customers are, and what products/services they buy together, we can take a number of paths from here. A dynamics marketing list could be the start of a marketing campaign. A workflow or a plugin could help us detect possible upsell opportunities in real-time. For simplicity, I’ve used a simple macro in Excel to create a number of leads for customers who did buy a House Loan Account, but did not buy a House Loan Insurance. Here are the new leads in CRM.
 Conclusion
Conclusion
This blog post shows just the tip of the iceberg. The combined power of Dynamics CRM and SQL Server offers a huge land of opportunities to get better understanding and actionable insights on your customers.
Manuel
This post was originally published on https://markmargolis.wordpress.com. This posting is provided “AS IS” with no warranties, and confers no rights.
Next time on Mark Margolis’s Blog: Power Map (GeoFlow) for Microsoft Dynamics CRM

Reblogged this on Mahender Pal and commented:
Very informative post regarding Data Mining with Microsoft Dynamics CRM
Excellent article indeed. I especially wanted to underline that you pushed the insight back into the Dynamics CRM environment. Many banks we work with want more out of their BI projects and integrating the data back into Dynamics CRM as an opportunity is an excellent illustration of this.
Great article again. Really shows the opportunities of data mining with CRM.
Really interesting article. Would it be possible to know how you put the data back into Dynamics. At the moment we have a very convoluted manual method of doing this using connections. Also very interested in using the vast amount of data we hold in our CRM for providing value back to the business